Words are a fundamental aspect of our life. They allow us to communicate our feelings, thoughts, emotions to the others.
Why not apply advanced maths to documents and try to automatically extract useful information? The right answer to this question names “text mining”, which is a mature discipline whose main concern is to develop automatic procedures which allow an “intelligent” read of a large quantity of documents. The aim is to extract useful information hidden in texts, highlight possible links and relations which could be invisible to a human being, proposing effective classifications of the document and facilitating a fast search of relevant documents.
These techniques have gained the attention of the scientific community with the advent of Internet, the largest library we have today.
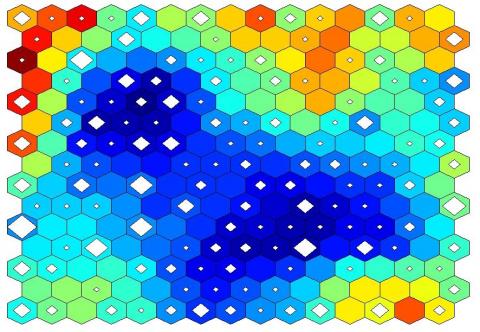
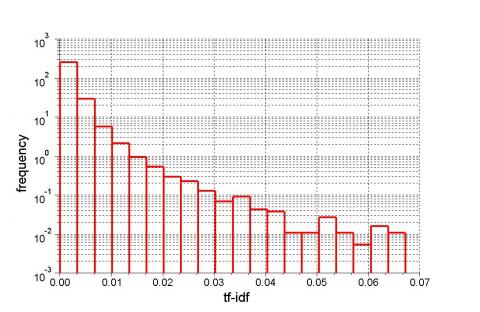
With this paper we would like to show how it is possible to easily implement a text classifier with Scilab, the classifier is based on the use of self organizing maps (SOMs) . We explore a corpus made of all the English papers appeared on the EnginSoft newsletter last years in order to have a mathematical description of our community. The result is really surprising: we get a sort of paint summarizing interests and relationships of EnginSoft world.
Do not hesitate to contact us for more details.
| Attachment | Size |
|---|---|
| 1.62 MB |
 representing the corpus")



 representing the corpus")




{kind=link}
{kind=link}
{kind=link}
{kind=link}